lingdata
Сайт курса «Лингвистические данные», бакалавры 1 курс НИУ ВШЭ
Объединение данных из разных таблиц с помощью индексации
Предположим, мы хотим объединить две имеющиеся у нас таблицы в одну. Как это сделать? Сегодня мы разберем это на примере.
В этом семинаре будем использовать данные социолингвистического эксперимента, который проводили первокурсники в январе 2019 года. Страница исследования на vastry.
Возьмём две таблицы: данные лингвистического эксперимента и результаты теста на знание английского языка.
Вот ссылка на гугл-таблицу, сделайте себе копию или скачайте.
Таблица с данными о произношении sounds
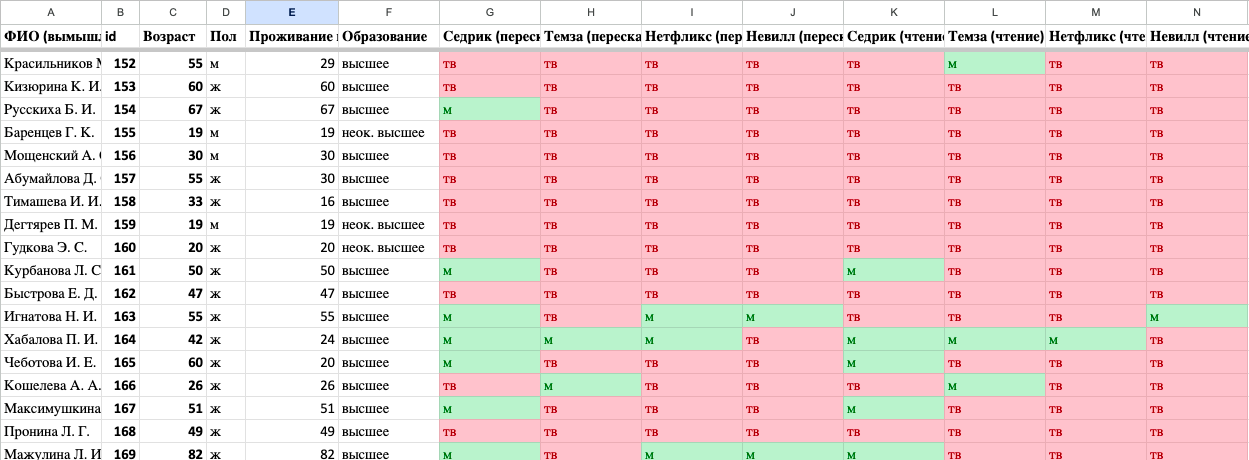
Таблица с данными о владении английским english
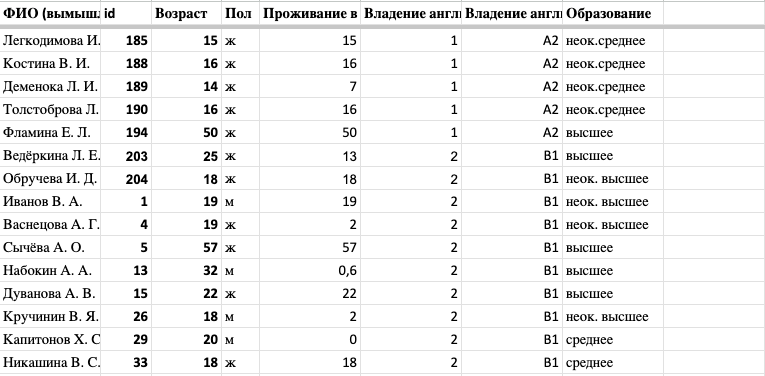
Мы хотим получить общую таблицу, где данные из двух таблиц сведены вместе и можно сделать вывод о влиянии социолингвистических параметров (особенно уровня владения английским языком) на произношение переднеязычных зубных согласных [т], [с], [н] перед ударным е в именах собственных англоязычного происхождения.
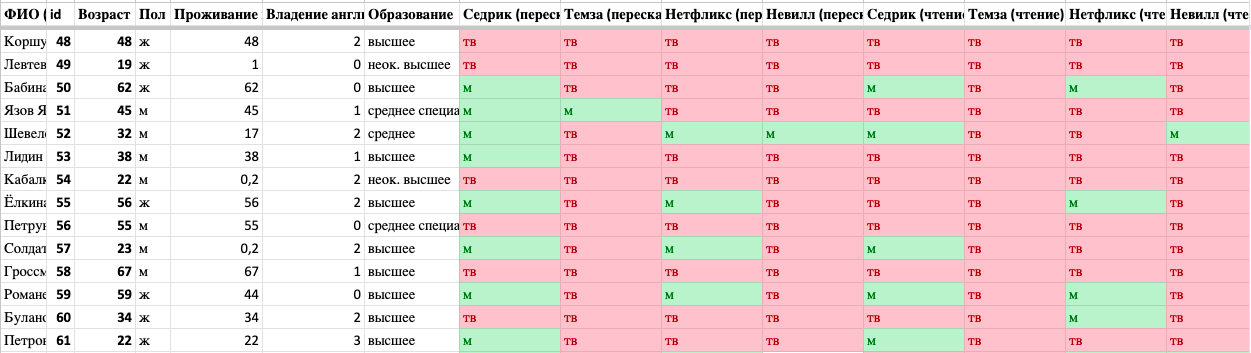
Внимание, в получившейся таблице могут и должны будут встречаться пустые ячейки!
Что нужно делать:
Шаг 1.
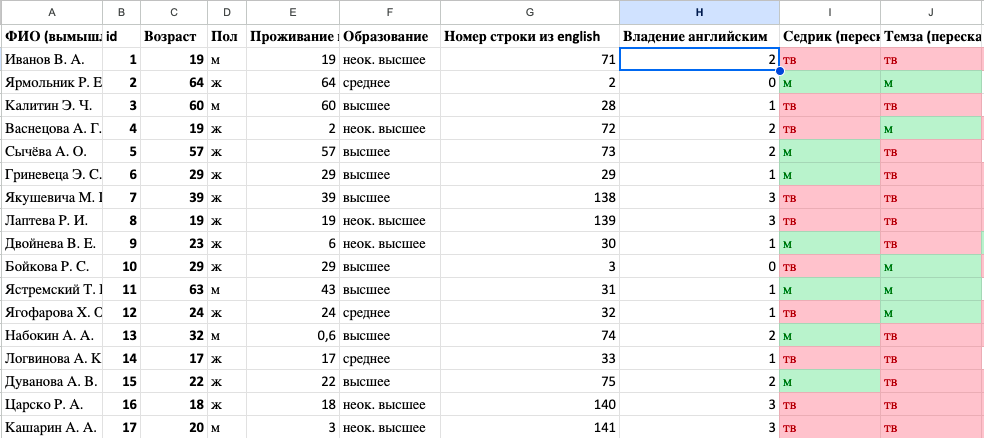
Добавим в таблицу sounds столбец c номером строки, на которой информант (id) стоит в таблице english.
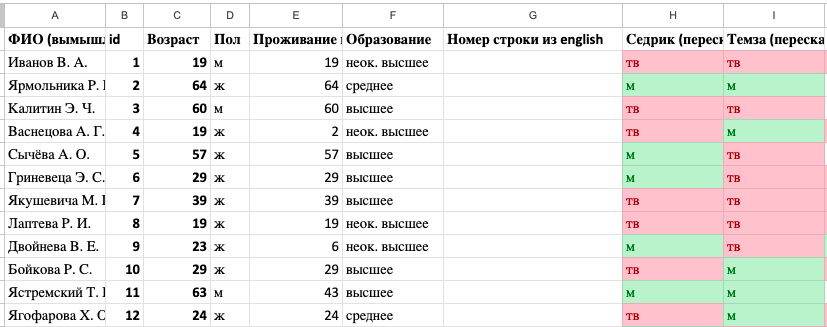
Шаг 2.
Затем для каждого информанта в таблице sounds нужно:
- найти его в столбце “id” таблицы
english - определить номер строки, на которой он стоит
- записать этот номер в столбец “Номер…” таблицы
sounds
Сделаем это с помощью формулы =ПОИСКПОЗ(...) (в английской версии =MATCH(...)).
В Excel эту формулу можно найти на вкладке Формулы в разделе “Ссылки и массивы”.

В окне вставки формул укажем три аргумента:
- Искомое_значение: кликните на ячейку с id информанта.
- Просматриваемый массив: затем перейдите на лист таблицы
englishи выделите столбец “id” - Тип сопоставления: 0 (обозначает точное совпадение).
Нажмем OK.
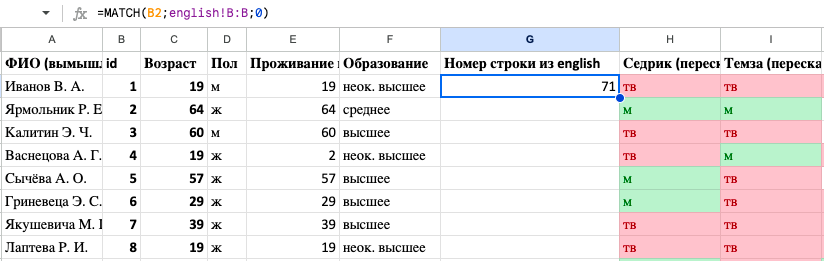
В ячейке должен отобразиться номер строки, на которой искомое слово стоит в таблице english. Проверьте (с помощью поиска), что номер правильный.
Скопируем ячейку с формулой и вставим ее в том же столбце напротив всех остальных слов (можно дважды кликнуть на правый нижний угол заполненной ячейки, чтобы ее формула автоматически растянулась на весь столбец; выделение можно также растянуть на весь диапазон до конца таблицы, пользуясь комбинацией горячих клавиш Shift + Ctrl + стрелка вниз).
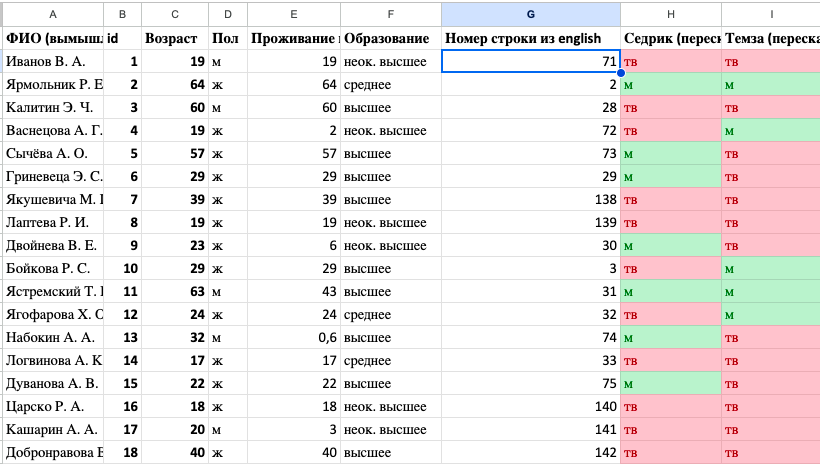
NB Пересчет значений ячеек может занять некоторое время, особенно для больших таблиц. Если после пересчета значений в каких-то ячейках появится #Н/Д (в английской версии - #N/A), это означает, что строка с таким словом не найдена.
Шаг 3
Добавим в таблицу sounds столбец “Владение английским”.
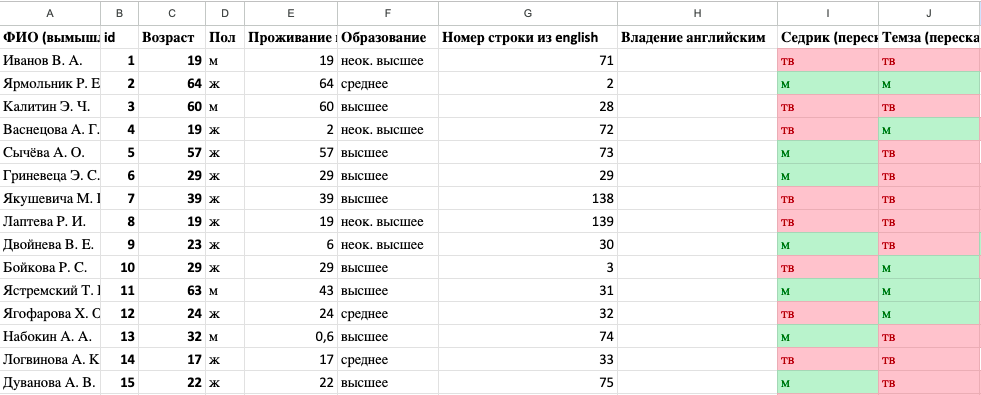
Шаг 4
На вкладке Формулы в разделе “Ссылки и массивы” найдем формулу “ИНДЕКС” (в английской версии “INDEX”), и в открывшемся мастере формулы:
- выберите первую опцию

- Массив: перейдите на лист
englishи выделите столбец с данными о владении английским. - Номер_строки: поставьте курсор на поле “Номер…” в таблице
sounds - Номер_столбца: оставьте пустым, так как мы работаем с одним столбцом.
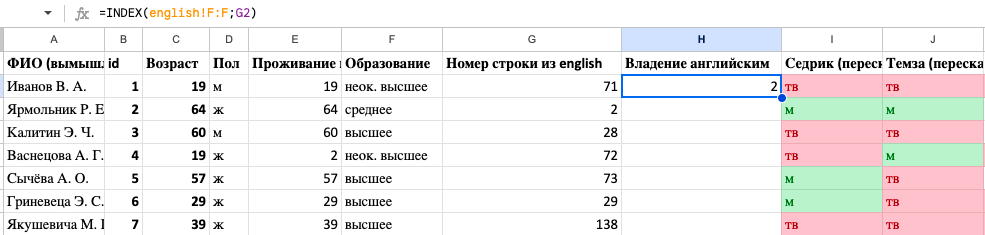
Нажмите ОК.
Проверьте (с помощью поиска), что уровень английского для данного информанта указан правильно. Скопируем ячейку с формулой и вставим ее напротив всех остальных информантов.
Скопируйте столбец с формулой ИНДЕКС/INDEX и вставьте его как значения (на то же место). Берегите природу, не заставляйте редактор пересчитывать формулы бесконечно, если этого не требуется.
Теперь мы переставили все найденные данные из таблицы english. Осталось добавить те слова из english, которых не нашлось в основной таблице.
Шаг 5
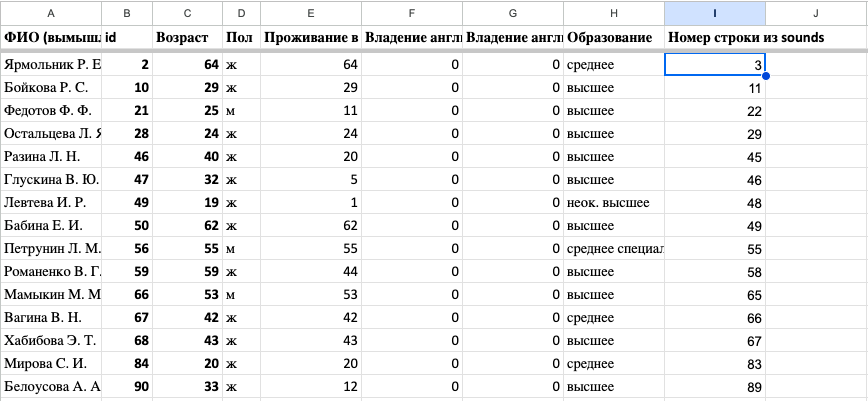
Теперь все будет наоборот: добавим в таблицу english столбец “Номер строки, на которой информант стоит в sounds”.
Шаг 6
Для каждого слова в таблице english найдем его позицию в столбце со словами таблицы sounds и запишем в столбце “Номер строки…” (так же, как в Шаге 2).
Шаг 7
Теперь мы хотим взять из таблицы english только те слова, которых не нашлось в списке sounds.
Для этого отфильтруем все ячейки со значением “#Н/Д” в столбце “Номер строки…”.
Делается это так:
- Выделяем всю таблицу, нажав на ее левый верхний угол.
- На вкладке “Данные” ищем функцию “Фильтр”, нажимаем.
- Выбираем нужную нам колонку “Номер строки…”, нажав на небольшую белую кнопку справа от ее названия.
- Создаем и применяем фильтр с условием “равно…” и значением “#Н/Д” (или “equals” “#N/A” в англоязычном интерфейсе).
- Готово, теперь у нас остались только нужные слова!
Если отфильтровать слова почему-то не удалось, можно попробовать отсортировать их по значению столбца “Номер строки…”. Так все слова со значением “#Н/Д” в этом столбце окажутся внизу или вверху таблицы, и их можно будет скопировать вручную.

Теперь добавим данные по этим словам в таблицу sounds (тут можно просто скопировать нужные данные в правильные столбцы).
Примечание: если вам не удается вставить скопировать слова на другую вкладку, значит, вы пытаетесь вставить содержание целого столбца в часть другого столбца, что невозможно. Выделите именно диапазон ячеек от первого до последнего информанта.
Шаг 8
Теперь у нас в таблице sounds сведены все данные!
Замените все вхождения #Н/Д на пустую строку.
УРА!
Визуализации
Посмотрите, какие факторы влияют на произношение и как.
Нарисуйте графики, на которых будет видно, насколько часто смягчают согласные перед е люди разного возраста, пола, с разным уровнем образования и английского, не забыв, что у нас есть данные о произношении при двух условиях (чтение и пересказ).
Вот, что получилось у первокурсников в 2019 году:
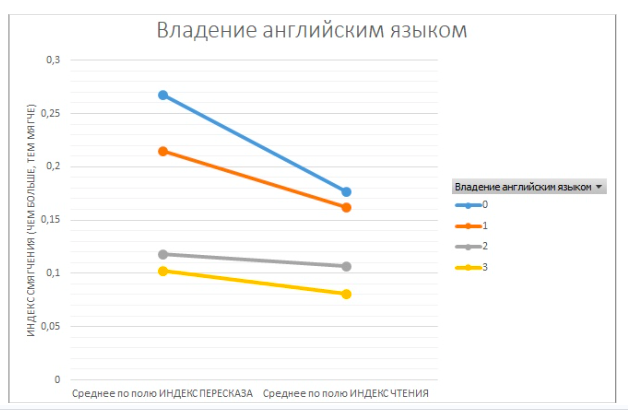
Гугл-таблица с некоторыми визуализациями.