lingdata
Сайт курса «Лингвистические данные», бакалавры 1 курс НИУ ВШЭ
Web-корпуса. Aranea, SkELL, SketchEngine. Коллокации. Совместная встречаемость.
http://aranea.juls.savba.sk/ (http://unesco.uniba.sk/guest/)
Мы будем работать с семейством корпусов Aranea – зайдите по ссылке Guest Access и выберите English Araneum Anglicum Minus (120 млн слов).
Aranea Web Corpora - семейство сравнимых веб-корпусов. Есть для большого количества языков:
- Anglicum - английский (Anglicum Africanum - африканский английский, Anglicum Asiaticum - азиатский английский)
- Bohemicum - чешский
- Bulgaricum - болгарский
- Finnicum - финский
- Francogallicum - французский
- Georgianum - грузинский
- Germanicum -немецкий
- Hispanicum -испанский
- Hungaricum -венгерский
- Italicum - итальянский
- Nederlandicum - голландский
- Polonicum - польский
- Russicum - русский
- Sinicum - китайский
- Slovacum - словацкий и т.д.
Что значит сравнимых?
Очевидно, что мы не можем сравнивать данные художественных текстов на английском языке 19 века и устную речь на русском языке 21 века. Однако иногда нужно проводить кросс-лингвистические исследования, и тогда нужны корпуса на разных языках не с одинаковыми (как в параллельном корпусе), а с похожими текстами. С помощью корпусов семейства Aranea можно проводить такие исследования. Все эти корпуса содержат тексты примерно с примерно одинаковым распределением текстов по времени (в основном современные тексты), стилям и тематикам (например, мы можем предположить, что тематики новостей примерно одинаковы в разных странах).
Что значит веб-корпус?
Эти корпуса были созданы посредством обкачивания Интернет-ресурсов на соответствующих языках. Что хорошо - много данных! Что плохо - нужно уделить особое внимание предобработке текстов. Основные проблемы: дублирующиеся тексты и опечатки, включая те, что возникли во время скачивания текста с веб-страниц.
Типы поиска
- леммы - искать все словоформы, имеющие данную лемму
- словоформы - искать конкретную словоформу
- фразы - искать несколько словоформ в цепочке
- CQL (Corpus Query Language) - гибкий язык, позволяющий делать сложные запросы
Как делать запросы на CQL
Вот тут отлично написано. Ключевые моменты:
- Каждое слово задаётся квадратными скобками
[]. - Внутри этих скобок мы пишет атрибут, по которому хотим искать слово, и его значение. Например,
[word="mothers"]ищет все случаи употребления словоформыmothers, а[lemma="mother"]ищет все слова с леммойmother(предыдущий запрос тоже сюда попадёт). - Неоднословный запрос:
[word="every"] [word="so"] [word="often"]. Квадратные скобки лучше отделить пробелом. - Атрибуты такие: lemma, word, lempos, tag (и несколько других)
- Теги tag перечислены тут – https://www.cis.uni-muenchen.de/~schmid/tools/TreeTagger/data/Penn-Treebank-Tagset.pdf#page=7
Корпуса размечены также в паре других форматов – atag (Aranea universal tags) и ztag. - Атрибуты можно сочетать:
[word="test" & tag!="V.*"][word="test" & !tag="V.*"][!(word="test" & tag="V.*")][word="test.*" & (tag="VVN" | tag="VP")]
- Можно искать слова, идущие не подряд:
"confuse.*" []{0,10} [tag="IN" | tag="PP"]- от 0 до 10 слов может стоять между словом, начинающимся сconfuseи предлогом или личным местоимением. - Запрос
[tag="N.*"] within [tag="J.*"] [tag="N.*"]найдёт существительные, слева от которых в левом контексте прилагательные (не выделенные красным) - Ну и можно ещё много чего, об этом подробнее по ссылке.
Что можно делать?
View options: настраивать видимость тегов разметки, менять формат выдачи - KWIC (Key Word In a Context = конкорданс), по предложениямSort: сортировать - по правому контексту, по левому контексту, по найденной форме (Node), случайным образом (Shuffle)Frequency: смотреть данные о частотности и распределении найденных элементов в корпусе - какой части речи больше, какой формы больше и т.д.Collocation: искать коллокацииSampleиFilter- делать выборки и фильтровать выдачуSave: сохранять выдачу к себе на компьютер
Задание для самостоятельной работы: В отличие от русского глагола подтвердить, английский глагол support не может присоединять изъяснительную клаузу с that непосредственно, он требует прямого дополнения (ср. to support an idea that…).
- составьте запрос с использованием CQL, который должен искать глагол support во всех формах, существительное, которое отстоит от него не далее чем на 3 слова, и that
- оставьте в выдаче по одному примеру из документа, используя фильтр
- отсортируйте выдачу по искомому фрагменту (Node)
- составьте частотный список (Frequency), используя Node forms. Каков самый частотный фрагмент и какова его частотность?
- составьте другой частотный список, используя Node tags. Найдите самый частотный элемент списка, в котором после глагола употребляется не артикль, а слово другой части речи. Что это за часть речи? (Подсказка: кликнув на
P(positive examples) слева, вы можете увидеть все примеры выдачи, соответствующие элементу частотного списка.)
Существительные в позиции прямого дополнения support.
- в этой части вам нужно составить три более коротких запроса, в которых после глагола support идет неопределенный артикль, определенный артикль и притяжательное местоимение, соответственно.
- для каждой выдачи, составьте список коллокатов (Collocations), которые стоят от справа найденного фрагмента (их может отделять от фрагмента максимум одно слово). Коллокаты должны встречаться не менее 10 раз во всем корпусе и не менее 3 раз в данном окне. Сортируя списки коллокатов по LogDice, сохраните их в виде CSV файла к себе на компьютер. Сравните топ-10 в трех получившихся списках коллокатов (после неопределенного, неопределенного артикля и притяжательного местоимения).
- в последнем списке коллокатов, сравните сортировку выдачи по LogDice и T-score.
Что такое коллокации?
Как вам нравятся такие предложения:
I hope to succeed the goal.
The tailor operated on my sleeves.
I highly disagree with the opinion.
Что-то не то, правда?
Ещё парочка примеров:
| Можно сказать | Нельзя сказать |
|---|---|
|
|
Коллокацией называется словосочетание, имеющее признаки синтаксически и семантически целостной единицы, в которой выбор одного слова диктует выбор другого. Коллокации - не идиомы!
Разные лингвистические свойства коллокаций
{kind=link}
Откуда берутся коллокации?
Не совсем понятно, почему именно эти два (или больше) слова объединяются в целостную единицу. Это может быть продиктовано даже простой традицией. Однако совершенно ясно, как можно искать коллокации! Нужно искать два слова, которые часто встречаются вместе. Но так ли всё просто?
Предположим, что слова в языке стоят в случайном порядке и их сочетаемость имеет случайный характер. Давайте ссыплем все слова из корпуса в большой мешок, перемешаем, распределим случайным образом по мешочкам-текстам, а далее выложим по канавкам-предложениям. Оценим вероятность того, что два слова окажутся рядом. Если гипотеза верна, то вероятность появления биграмма on in окажется весьма велика, да и сочетание also suggest будет вполне предсказуема, так как каждое из слов встречается с большой частотой. Вместе с тем, вероятность случайного появления рядом слов heartily и endorse (да еще именно в таком порядке) чрезвычайно мала - ведь каждое слово довольно редкое. Можно понять, что сочетаемость слов имеет разную “цену”, или значимость.

Разные оценки связи
Некоторые слова встречаются рядом чаще, чем другие, но не всякий N-gram является лингвистически интересным (ср. at the). Для того, чтобы показать, что связь между словами не случайна, придуманы разные формулы, они по-разному ранжируют коллокации, см. подробнее:
- MI (коэффициент взаимной информации)
- T-score
- log-likelihood (коэффициент логарифмического правдоподобия)
- Dice (Дайс)
🤔 Можно ли по корпусной выдаче понять, в чём между ними разница?
BNC на платформе NoSketchEngine
Полезные функции:
- Compare
Задание для самостоятельной работы: Cравните сочетаемость слов aware и familiar – например, какие глаголы употребляются непосредственно слева от них.

SkELL
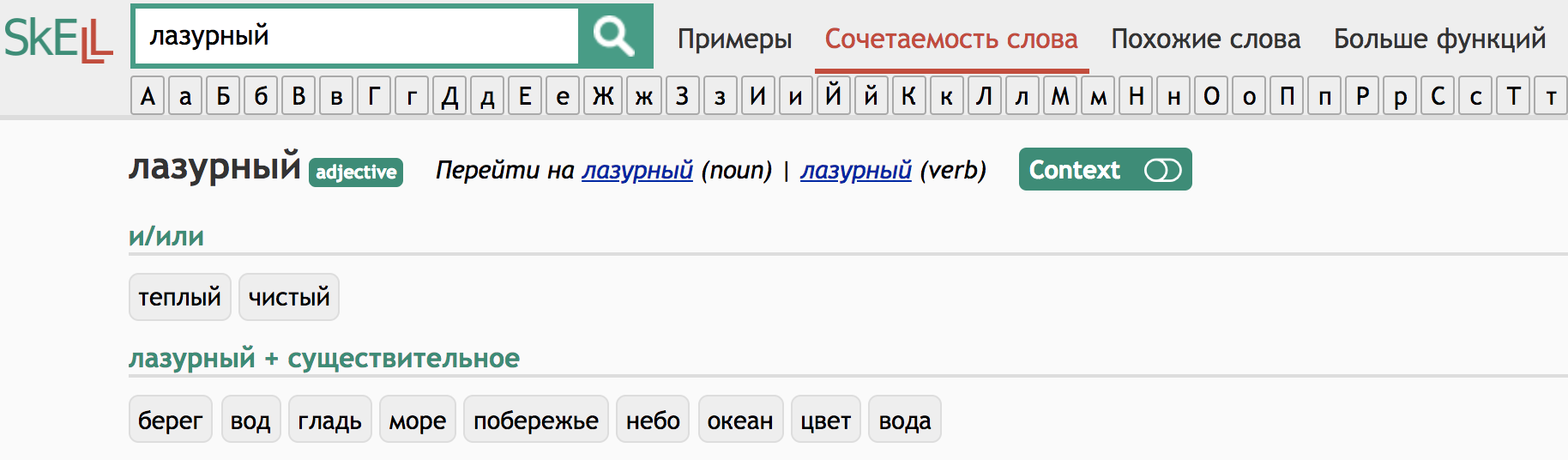
SkELL – открытые корпуса SketchEngine для изучающих иностранный язык. Основные функции:
- корпуса объемом около 1 млн. словоупотреблений, отобранные из большого интернет-корпуса (TenTen)
- слово в контексте
- сочетаемость слова (word sketches)
- похожие слова (облако слов)
Открытые корпуса Sketch Engine
British Academic Written English Corpus (BAWE)
Полезные функции:
- word list – например, списки 3-граммов
- word sketch – сочетаемость слова, по синтаксическим конструкциям (например, для слова matter)
- thesaurus – близкие по смыслу слова (например, для глагола suggest)
- sketch diff – различия в сочетаемости двух слов (например, для assume и suggest)
Большие корпуса SketchEngine – enTenTen, ruTenTen, deTenTen, arTenTen – в платном доступе (пробный бесплатный доступ на 30 дней). Также есть опция создавать свои корпуса, в том числе параллельные.
Дополнительные задания: https://docs.google.com/document/d/1DEzUg6ugAJB6lVk-CplARI6w3qBBqK-UPWRdRPPiURM/edit
Другие платформы для работы в веб-корпусами:
- KonText – требуется регистрация
- http://corpus.leeds.ac.uk/internet.html – платформа Сергея Шарова (Университет Лидса), корпуса проекта WaCky! – коллокации, частотные списки, язык запросов CQP (похож на CQL).