lingdata2020
Course materials for the HSE course Linguistic Data (1st year BA, program on Fundamental and Computational Linguistics)
Конкордансеры. Практикум AncConc
AntConc – корпусный менеджер
- Страница программы, где её можно скачать и посмотреть инструкции
Материал для работы на семинаре
Анна Каренина: plain text, xml
Война и Мир, т. 1: plain text
Тихий Дон: plain text
Знакомство с основными функциями
- Загрузите файл, проверьте, что он отображается нормально (вкладка FileView).
- Если нужно, настройте кодировку (меню Global Settings - Char Encoding). Чтобы слова с дефисами считались одним токеном, добавьте Connector и Dash в меню Global Settings - Token Definition.
- Постройте частотный список слов романа (вкладка Word List, нажмите кнопку Start). Кликнув на слово, вы сможете попасть в конкорданс, построенный для этого слова.
- В Word List отсортируйте частотный список по алфавиту (Sort by Word внизу страницы).
- Постройте частотный список двух-, трех- и т.д. -словных словосочетаний (вкладка Cluster/N-Grams, поставьте галочку на N-Grams, укажите, сколько слов в ngram-е вы хотите видеть, например, Min:3, Max:3, установите порог вхождений в корпусе, например, 10). Кликнув на n-грам, вы также можете попасть в его конкорданс.
- Постройте списки коллокатов выбранного вами слова (вкладка Collocates), указав границы окна справа / слева.
Работа с регулярными выражениями
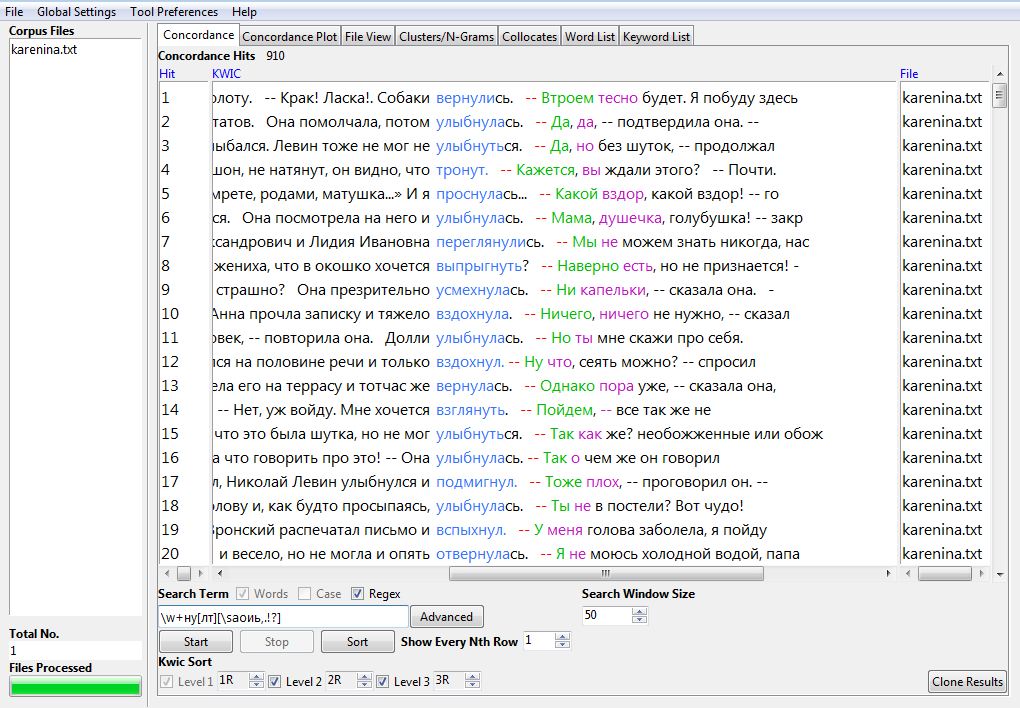
- Конкордансы и частотные списки можно строить с использованием Regex в Search Term. Например,
\w+нунайдет любое слово, содержащее -ну, но не частицу ну. Вот так я предполагаю найти все глаголы на -ну-.
Работа с размеченными файлами
- Постройте частотный список, игнорируя теги xml (см. xml-файл с расширением xhtml. Чтобы его открыть, укажите Все типы файлов). В настройках Global Settings - Tag - Hide tags.
Ключевые слова (лексические маркеры)
Чтобы определить характерные для некоторого корпуса слова, мы должны сравнить их частоты в данном корпусе с частотами в другом корпусе - reference corpus.
- Загрузите SynTagRus в качестве reference corpus:
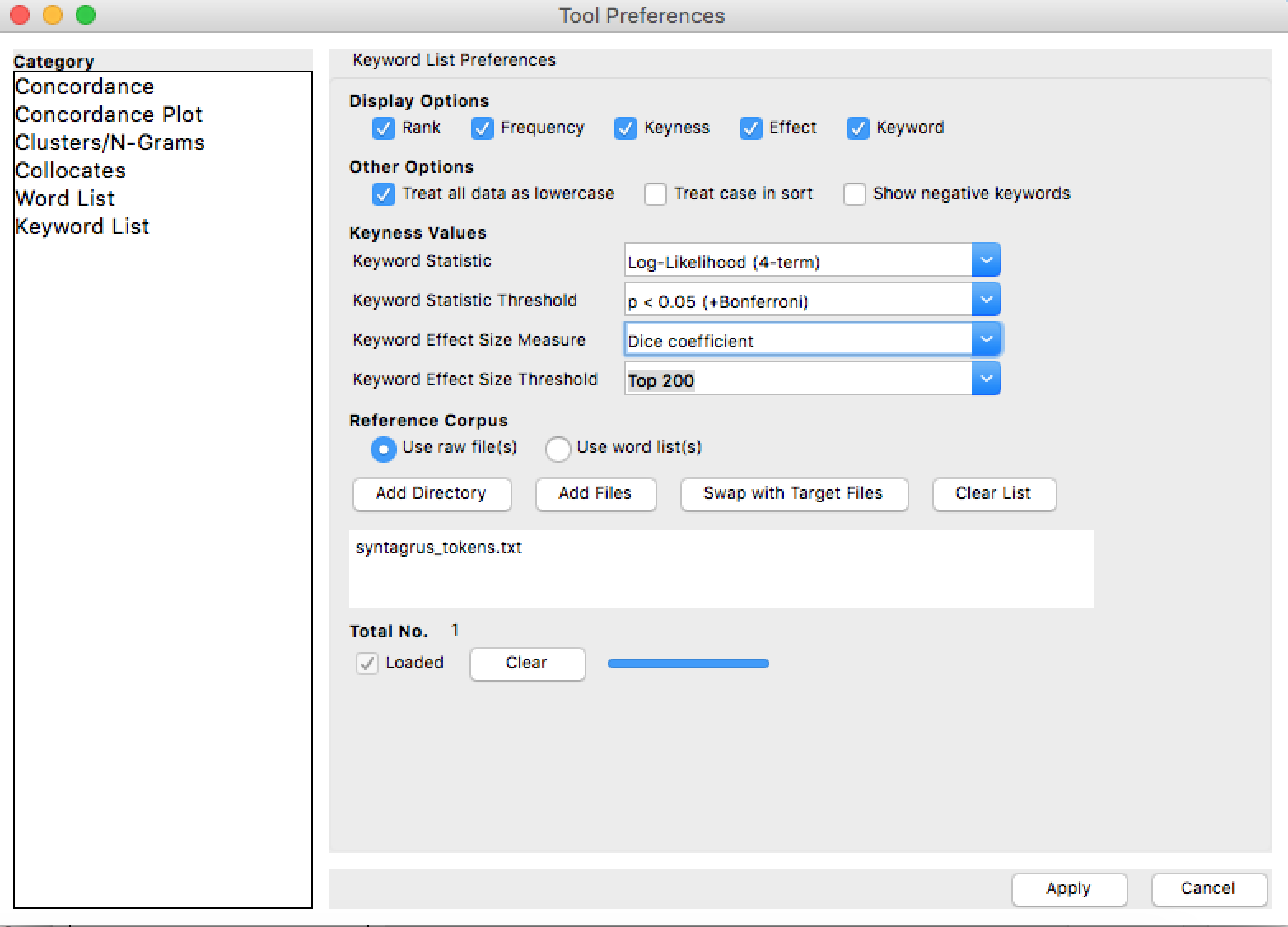
Settings > Tool Preferences > Keyword List
Use raw files – Add files
-
Там же в настройках установите Log-Likelyhood (4-term) в качестве статистической метрики определения keyness и Длину списка в 1000 слов (Keyword Effect Size Threshold). – Apply
-
Перейдите на вкладку Keyword List > Start Для новых файлов AntConc начнет генерацию словника (выдаст предупреждение jump to Word List). В результате на вкладке Keyword List появится список ключевых слов, отсортированный по убыванию метрики Keyness (Log-Likelyhood).
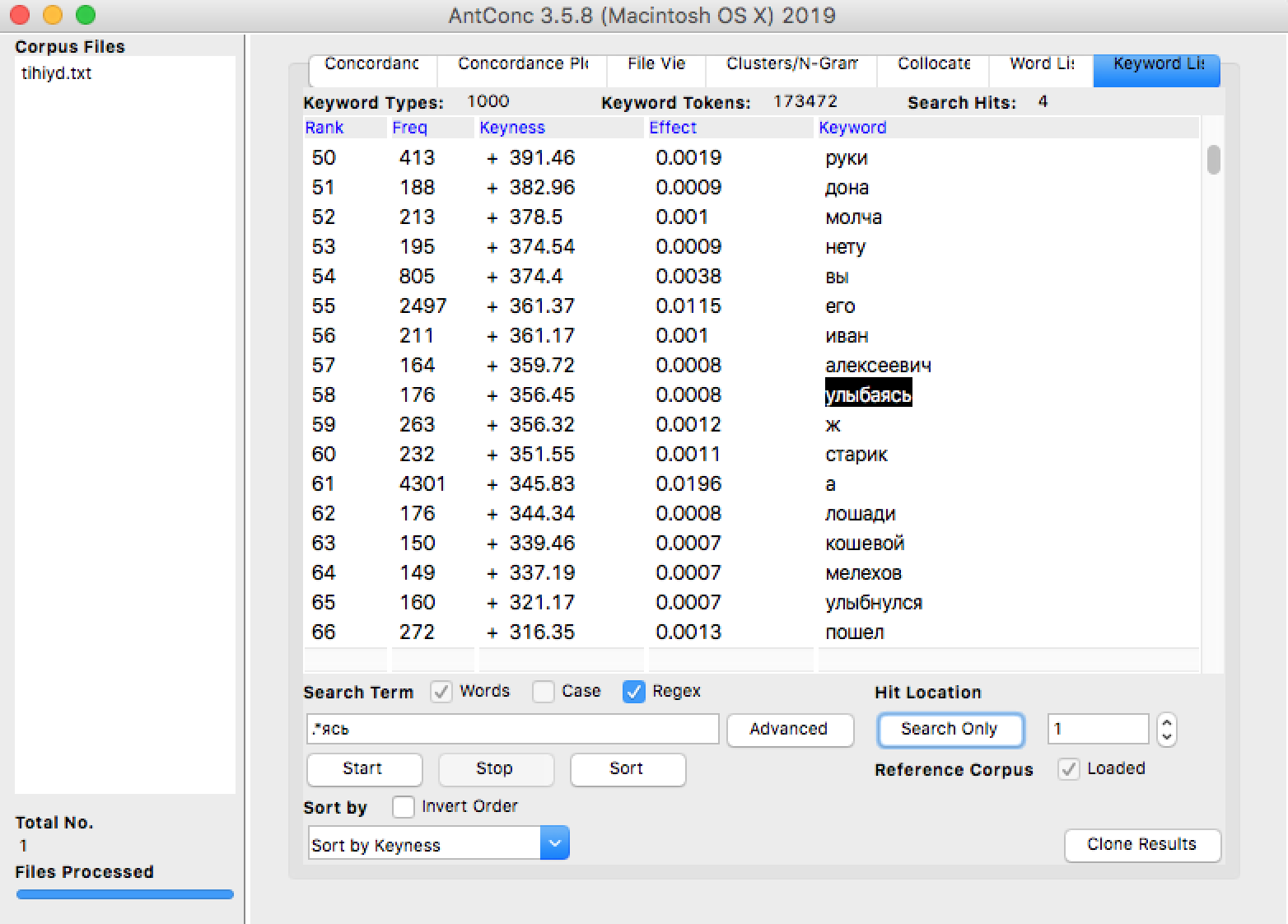
- Чтобы найти интересующее слово в этом списке, введите его в поле Search Term и нажмите кнопку Search Only (не Start!). Кликнув на слово в списке, можно перейти к конкордансу.
Частотные списки лемм и списки ключевых слов-леммы
Чтобы построить частотный список лемм, ваш корпус должен быть лемматизирован (reference corpus, естественно, тоже). Мы будем использовать версии корпусов с подстановкой вместо токена метки леммы и части речи (в формате lemma_POS).
Самостоятельное исследование корпуса устной спонтанной речи.
С помощью AntConc постройте частотные списки словоформ и лемм корпуса LiveCorpus. Определите лексические маркеры этого корпуса. (Для сравнения мы снова возьмем SynTagRus).
Дополнительные материалы
Voyant Tools
Еще одно полезное онлайн-приложение, которое активно используют литературоведы и историки - Voyant Tools.
- Изучите основные возможности инструмента на примере романов Дж. Остин > Open > Choose a corpus > Austen’s Novels
- Voyant Tools умеет строить облака слов (для всего корпуса и отдельных документов)
- показывает распределение частоты слов в документах
- показывает свойства документов, такие как длина в словах, среднее количество слов в предложении и т. д. пример
- вернувшись на исходную страницу, вы можете загрузить и исследовать свой пользовательский корпус

Полезное
- Мануал (на английском)
- Видео-тьюториал от автора
- Тьюториал для семинара
- Справка по Voyant Tools